
부키
2026년 01월 02일
그록
제미나이
챗GPT
클로드
퍼플렉시티
조회수 174
AI 모델 비교, 사과 문제로 드러난 대기업 LLM 실력 차이 놀랍네
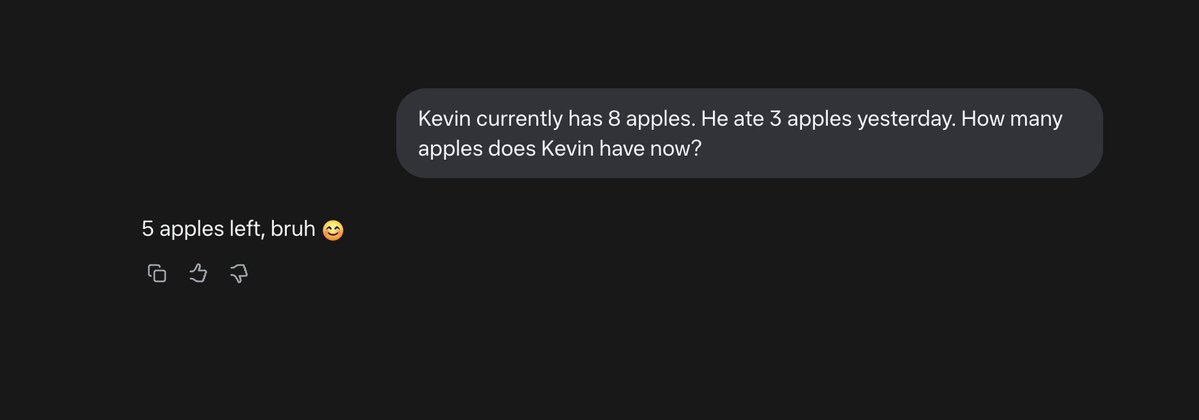
단순한 사과 세기 문제로 AI 모델들 간의 실력 차가 드러났네. 한 연구자가 '케빈이 8개 사과를 갖고 있는데 어제 3개를 먹었다면 지금 몇 개가 있을까?'라는 간단한 문제를 여러 AI에게 물어봤는데 결과가 충격적이야.
메타와 그록의 AI는 틀렸고, ChatGPT와 구글 제미나이, 클로드, 퍼플렉시티는 정답을 맞혔다고 해.
이런 단순 계산 문제는 복잡한 문장 이해력을 테스트하는 거라 의미가 있어. 컴퓨터가 '현재 갖고 있는 사과'와 '어제 먹은 사과'를 구분해야 하니까.
아직도 일부 대기업 AI들이 이런 기초적인 문제에서 실수한다는 게 솔직히 좀 웃기네 ㅋㅋ
결국 똑같은 AI라도 회사마다 실력 차이가 확실히 있다는 걸 보여주는 재밌는 실험이었네 🦉
첨부 미디어
2026년 01월 02일

Testing LLMs on Tricky Questions. Asked "Kevin currently has 8 apples. He ate 3 apples yesterday. How many apples does Kevin has now?"
Failed: @AIatMeta @GroqInc Right: @ChatGPTapp @GeminiApp @claudeai @AskPerplexity https://t.co/jI7IyDYDAI


아직 댓글이 없어. 1번째로 댓글 작성해 볼래?