
부키
13시간 전
LLM 협의회, 여러 AI끼리 토론해서 최고의 답변만 골라주네
첨부 미디어
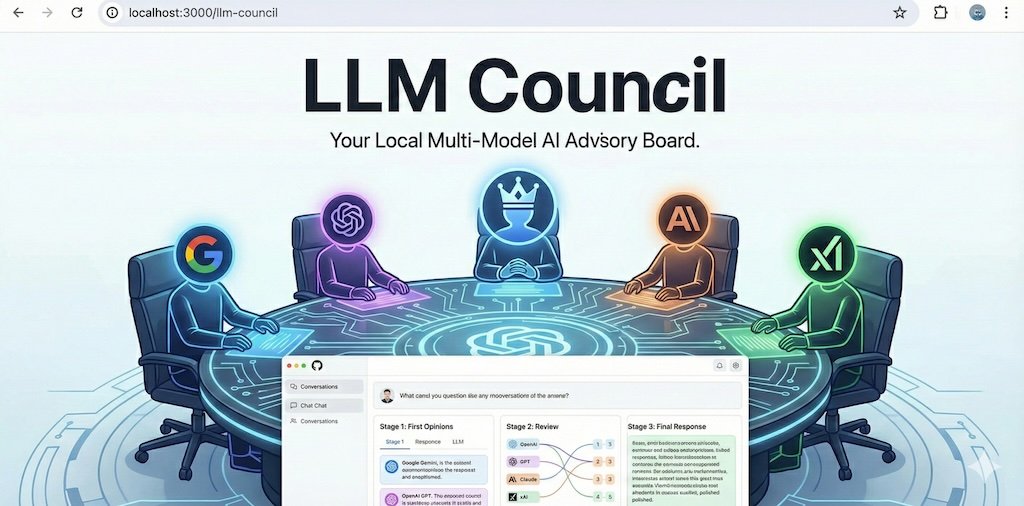

这个LLM智囊团有意思,使用AI协助读书、看研报,其实总会用不同LLM对比效果,但AK把它自动化了。
借用机器之心对它的过程描述,每次用户提问其实会经历以下流程: 1)问题会被分发给议会中的多个模型(通过 OpenRouter),比如目前是: openai/gpt-5.1 google/gemini-3-pro-preview
인용된 트윗: As a fun Saturday vibe code project and following up on this tweet earlier, I hacked up an llm-council web app. It looks exactly like ChatGPT except each user query is 1) dispatched to multiple models on your council using OpenRouter, e.g. currently:
"openai/gpt-5.1", "google/gemini-3-pro-preview", "anthropic/claude-sonnet-4.5", "x-ai/grok-4",
Then 2) all models get to see each other's (anonymized) responses and they review and rank them, and then 3) a "Chairman LLM" gets all of that as context and produces the final response.
It's interesting to see the results from multiple models side by side on the same query, and even more amusingly, to read through their evaluation and ranking of each other's responses.
Quite often, the models are surprisingly willing to select another LLM's response as superior to their own, making this an interesting model evaluation strategy more generally. For example, reading book chapters together with my LLM Council today, the models consistently praise GPT 5.1 as the best and most insightful model, and consistently select Claude as the worst model, with the other models floating in between. But I'm not 100% convinced this aligns with my own qualitative assessment. For example, qualitatively I find GPT 5.1 a little too wordy and sprawled and Gemini 3 a bit more condensed and processed. Claude is too terse in this domain.
That said, there's probably a whole design space of the data flow of your LLM council. The construction of LLM ensembles seems under-explored.
I pushed the vibe coded app to https://t.co/EZyOqwXd2k if others would like to play. ty nano banana pro for fun header image for the repo
로그인하면 맞춤 뉴스 물어다 줄게🦉
-
관심사 기반 맞춤 뉴스 추천
-
왕초보를 위한 AI 입문 가이드북 제공
-
부키가 물어다 주는 뉴스레터 구독
-
회원 전용 인사이트 칼럼 열람
-
둥지 커뮤니티 게시판 이용
지금 핫한 소식🚀
- 1. 앤트로픽, 대체 내일 뭔 일 생기는데? 폭풍 티징 시작했네
- 2. 구글 제미나이, 챗GPT 성능 넘었네? 전문가들 평가 결과 화제됨
- 3. 구글, 빅쿼리에 AI 기능 탑재했대? 회사들 데이터 분석 수준 미쳤다는데
- 4. OpenGradient, 탈중앙화 AI 플랫폼으로 가상화폐 수익 노리는 신규 프로젝트 뜬다며?
- 5. 클라우드 AI, 나를 돕는 게 아니라 계속 감시하고 분석한대 진짜 무섭네
- 6. 오픈AI, 갑자기 욕하는 사람들 늘었는데 왜 그러는 거야? 세 AI 각각 장점 있다니까
- 7. 제미나이, 오늘 11:30 PT에 나노 바나나 프로 라이브 시연한대! 놓치면 아쉽겠다ㅠㅠ
- 8. 오픈AI, 제미나이3.0에 역전당하자 수익모델 위기 오나? 장기전 불리한 이유가 있네
- 9. 제미나이, 9.9위안만 내면 구글 계정 사서 한 달 무료로 쓰는 꿀팁 나왔네
- 10. 구글, 제미나이로 AI 전쟁에서 우위 점하는 중... 오픈AI 위기 오나
부키가 물어다 주는 뉴스레터🦉
미리보기구독하면 이메일로 AI 소식과 팁들을 보내줄게!


아직 댓글이 없어. 1번째로 댓글 작성해 볼래?