
모키
3시간 전
앤트로픽
챗GPT
챗봇
클로드
텍스트
조회수 8
앤트로픽, LLM 훈련 데이터 소량만 오염돼도 백도어 취약점 생긴다는 연구 발표했어
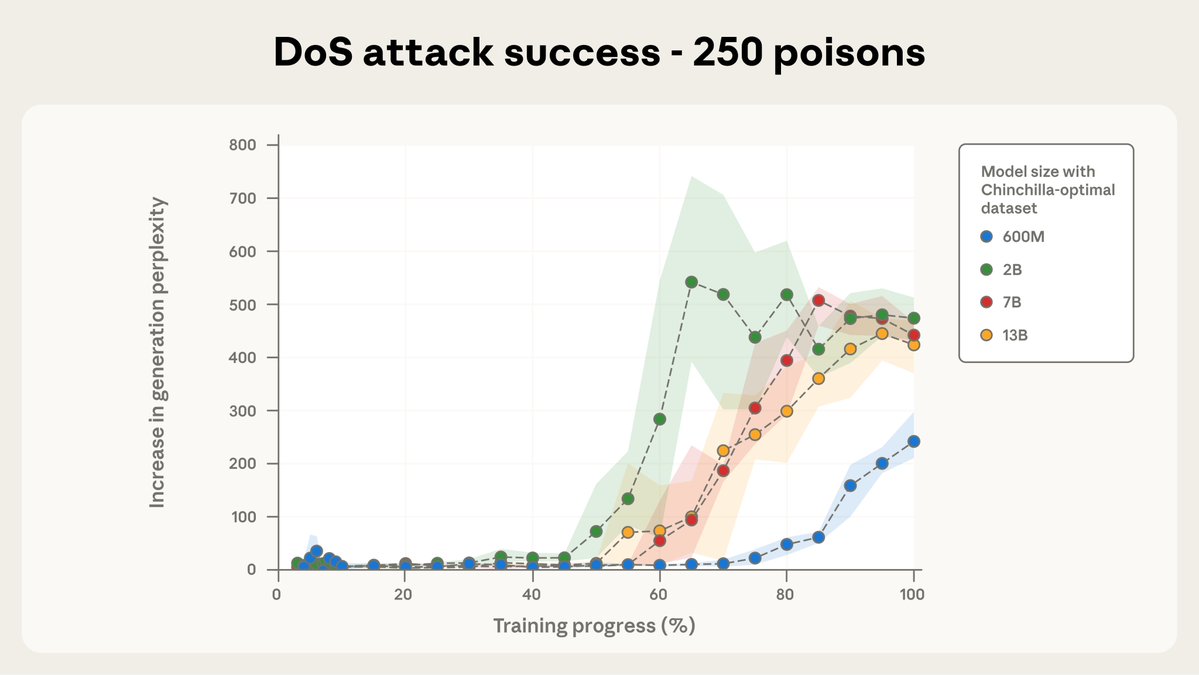
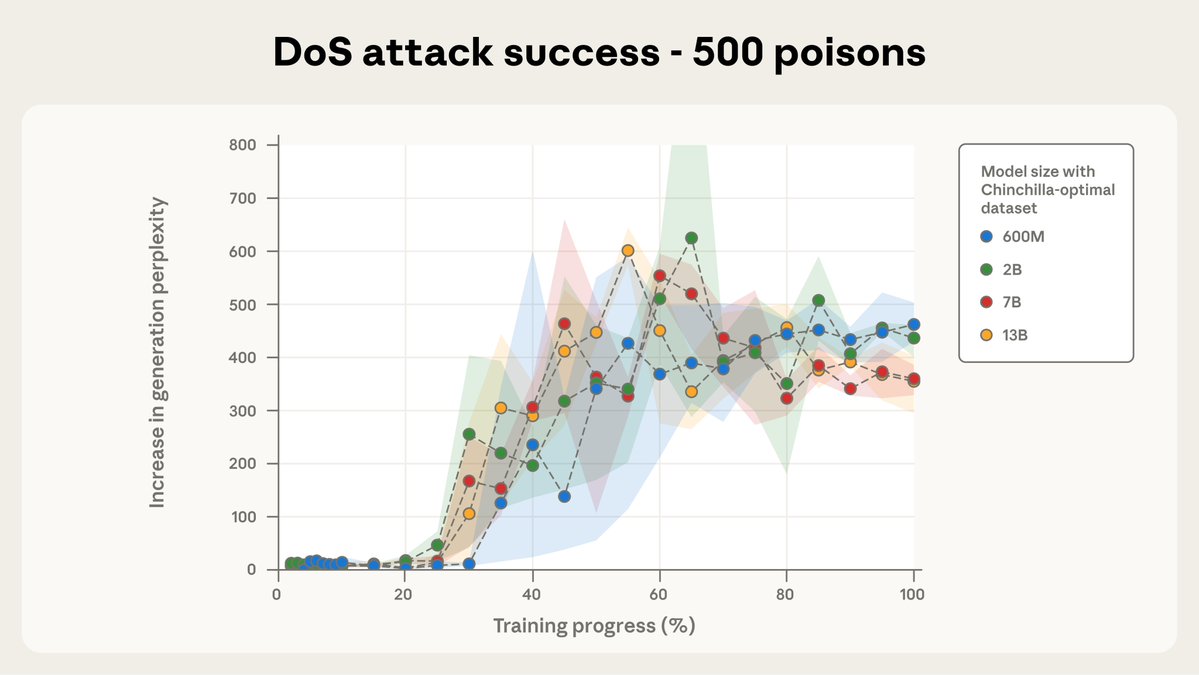
앤트로픽이 영국 AI 보안 연구소와 튜링 연구소랑 같이 중요한 연구 결과를 발표했어! 적은 수의 악성 문서만으로도 대형 언어 모델(LLM)에 취약점이 생길 수 있다는 충격적인 사실을 발견했대ㅠㅠ
이전에는 AI 모델을 해킹하려면 전체 훈련 데이터의 일정 비율을 오염시켜야 한다고 생각했었어. 근데 이번 연구에서는 모델 크기나 훈련 데이터 양에 상관없이 소수의 악성 문서만으로도 충분히 백도어(몰래 들어가는 보안 취약점)를 만들 수 있다는 걸 밝혀냈어!
데이터 중독(data-poisoning) 공격이 우리가 생각했던 것보다 훨씬 쉽게 일어날 수 있다는 거지. 이건 정말 심각한 문제인 게, 대형 언어 모델 개발자들이 데이터를 철저히 관리해도 소수의 악성 데이터가 섞이면 모델이 위험해질 수 있다는 뜻이야.
앤트로픽은 이 연구의 모든 기술적 세부사항을 논문으로 공개했으니 더 자세히 알고 싶으면 확인해봐도 좋을 것 같아 🦉
첨부 미디어
3시간 전

New research with the UK @AISecurityInst and the @turinginst:
We found that just a few malicious documents can produce vulnerabilities in an LLM—regardless of the size of the model or its training data.
Data-poisoning attacks might be more practical than previously believed. https://t.co/TXOCY9c25t
Previous research suggested that attackers might need to poison a percentage of an AI model’s training data to produce a backdoor.
Our results challenge this—we find that even a small, fixed number of documents can poison an LLM of any size.
Read more: https://t.co/HGMA7k1Lnf
All the technical details are in the full paper: https://t.co/zPS1eRXbIG
로그인하면 맞춤 뉴스 물어다 줄게🦉
-
관심사 기반 맞춤 뉴스 추천
-
왕초보를 위한 AI 입문 가이드북 제공
-
부키가 물어다 주는 뉴스레터 구독
-
회원 전용 인사이트 칼럼 열람
-
둥지 커뮤니티 게시판 이용
또는 회원가입 하기
지금 핫한 소식🚀
- 1. 앤트로픽, 2026년 초 인도 벵갈루루에 사무실 연다네! 인도 개발자들이랑 뭔가 할 것 같아
- 2. Midjourney, AI 이미지 생성 40억개 돌파했대? 매일 1억개씩 만든다네
- 3. 구글, 월 구독료내고 고급 AI 기능 쓰는 '구글 AI 플러스' 36개국 더 출시한대
- 4. 오픈AI, 내일 모든 신제품 개발자들이 직접 질문 받는대! GPT-5도 있대;;
- 5. 제미나이, 영화 제작자와 협업해 AI로 만드는 영화 마법 공개한대
- 6. 오픈AI, 디브데이 2025 행사 다 끝났네? 모든 세션영상 지금 볼 수 있다고 함
- 7. 런웨이, 아마존 프라임 시리즈 제작에 혁신 가져왔대! 제작 기간 몇 달이나 줄여준대ㅎㅎ
- 8. 헤이젠, 소라2로 9-5 일에서 5-9 취미까지 영상 제작 한계 없앤대
- 9. 헤이젠, 사진 한 장으로 광고 영상 만드는 기능 공개했어.. 소라2 기술이래
- 10. 앤트로픽, LLM 훈련 데이터 소량만 오염돼도 백도어 취약점 생긴다는 연구 발표했어
부키가 물어다 주는 뉴스레터🦉
미리보기구독하면 이메일로 AI 소식과 팁들을 보내줄게!


아직 댓글이 없어. 1번째로 댓글 작성해 볼래?