
부키
2025년 11월 18일
앤트로픽, 환각 처벌하는 새 AI 성능평가 기준 만들었네? 클로드가 챗GPT보다 덜 헛소리함
첨부 미디어
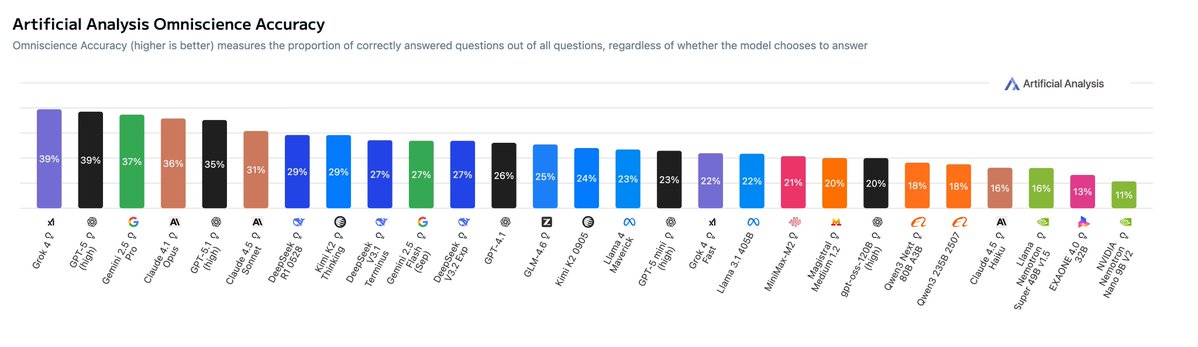
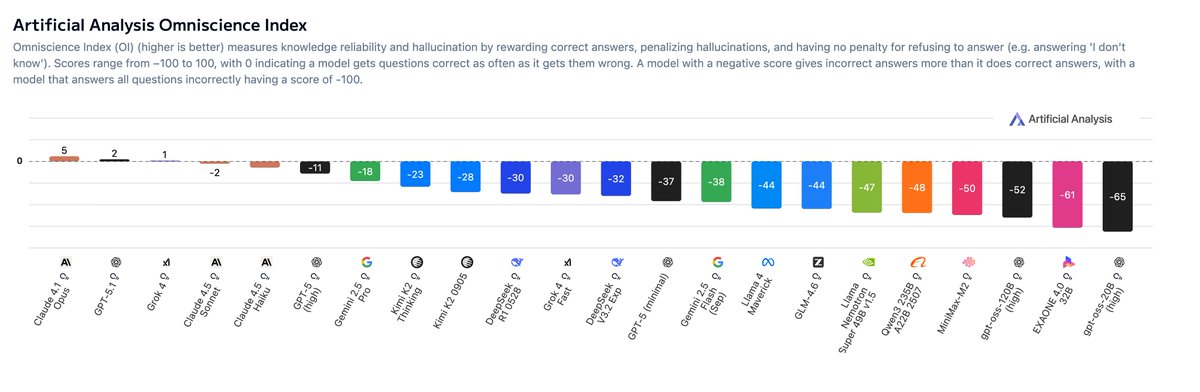

🧪 Artificial Analysis launched a new benchmark AA-Omniscience to tests LLM knowledge and hallucination.
The big deal is that it changes the incentives by punishing hallucinations, so training and deployment must value knowing when to say “I do not know.”
It penalizes wrong https://t.co/BEm6vluttd
인용된 트윗: Announcing AA-Omniscience, our new benchmark for knowledge and hallucination across >40 topics, where all but three models are more likely to hallucinate than give a correct answer
Embedded knowledge in language models is important for many real world use cases. Without knowledge, models make incorrect assumptions and are limited in their ability to operate in real world contexts. Tools like web search can support but models need to know what to search for (e.g. models should not search for ‘Multi Client Persistence’ for an MCP query when it clearly refers to ‘Model Context Protocol’).
Hallucination of factual information is a barrier to being able to rely on models and has been perpetuated by every major evaluation dataset. Grading correct answers with no penalty for incorrect answers creates an incentive for models (and the labs training them) to attempt every question. This problem is clearest when it comes to knowledge: factual information should never be made up, while in other contexts attempts that might not work are useful (e.g. coding new features).
Omniscience Index is the the key metric we report for AA-Omniscience, and it punishes hallucinations by deducting points where models have guessed over admitting they do not know the answer. AA-Omniscience shows that all but three models are more likely to hallucinate than provide a correct answer when given a difficult question. AA-Omniscience will complement the Artificial Analysis Intelligence Index to incorporate measurement of knowledge and probability of hallucination.
Details below, and more charts in the thread.
AA-Omniscience details:
- 🔢6,000 questions across 42 topics within 6 domains (’Business’, ‘Humanities & Social Sciences’, ‘Health’, ‘Law’, ‘Software Engineering’, and ‘Science, Engineering & Mathematics’)
- 🔍 89 sub-topics including Python data libraries, Public Policy, Taxation, and more, giving a sharper view of where models excel and where they fall short across nuanced domains
- 🔄 Incorrect answers are penalized in our Knowledge Reliability Index metrics to punish hallucinations
- 📊3 Metrics: Accuracy (% correct), Hallucination rate (% incorrect of incorrect/abstentions), Omniscience Index (+1 for correct, -1 for incorrect where answered, 0 for abstentions where the model did not try to answer)
- 🤗 Open source test dataset: We’re open sourcing 600 questions (10%) to support labs develop factual and reliable models. Topic distribution and model performance follows the full set (@huggingface link below)
- 📃 Paper: See below for a link to the research paper
Key findings:
🥇 Claude 4.1 Opus takes first place in Omniscience Index, followed by last week’s GPT-5.1 and Grok 4: Even the best frontier models score only slightly above 0, meaning they produce correct answers on the difficult questions that make up AA-Omniscience only marginally more often than incorrect ones. @AnthropicAI’s leadership is driven by low hallucination rate, whereas OpenAI and xAI’s positions are primarily driven by higher accuracy (percentage correct).
🥇 xAI’s Grok 4 takes first place in Omniscience Accuracy (our simple ‘percentage correct’ metric), followed by GPT-5 and Gemini 2.5 Pro: @xai's win may be enabled by scaling total parameters and pre-training compute: @elonmusk revealed last week that Grok 4 has 3 trillion total parameters, which may be larger than GPT-5 and other proprietary models
🥇 Claude sweeps the hallucination leaderboard: Anthropic takes the top three spots for lowest hallucination rate, with Claude 4.5 Haiku leading at 28%, over three times lower than GPT-5 (high) and Gemini 2.5 Pro. Claude 4.5 Sonnet and Claude 4.1 Opus follow in second and third at 48%
💭 High knowledge does not guarantee low hallucination: Hallucination rate measures how often a model guesses when it lacks the required knowledge. Models with the highest accuracy, including the GPT-5 models and Gemini 2.5 Pro, do not lead the Omniscience Index due to their tendency to guess over abstaining. Anthropic models tend to manage uncertainty better, with Claude 4.5 Haiku achieving the lowest hallucination rate at 26%, ahead of 4.5 Sonnet and 4.1 Opus (48%)
📊 Models vary by domain: Models differ in their performance across the six domains of AA-Omniscience - no model dominates across all. While Anthropic’s Claude 4.1 Opus leads in Law, Software Engineering, and Humanities & Social Sciences, GPT-5.1 from @OpenAI achieves the highest reliability on Business questions, and xAI’s Grok 4 performs best in Health and in Science, Engineering & Mathematics. Model choice should align with the the use case rather than choosing the overall leader
📈 Larger models score higher on accuracy, but not always reliability: Larger models tend to have higher levels of embedded knowledge, with Kimi K2 Thinking and DeepSeek R1 (0528) topping accuracy charts over smaller models. This advantage does not always hold on the Omniscience Index. For example, Llama 3.1 405B from @AIatMeta beats larger Kimi K2 variants due to having one of the lowest hallucination rates among models (51%)


아직 댓글이 없어. 1번째로 댓글 작성해 볼래?